An Unsupervised Normalization Algorithm for Noisy Text: A Case Study for Information Retrieval and Stance Detection
Abstract
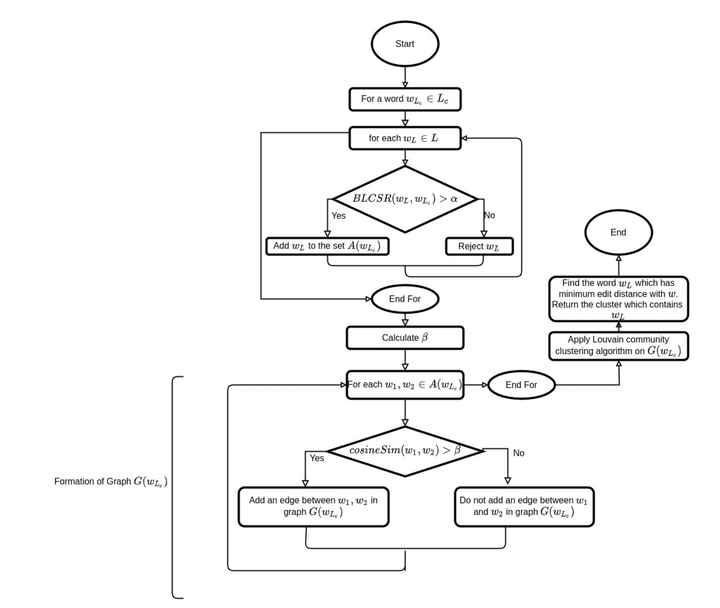
A large fraction of textual data available today contains various types of “noise,” such as OCR noise in digitized documents, noise due to informal writing style of users on microblogging sites, and so on. To enable tasks such as search/retrieval and classification over all the available data, we need robust algorithms for text normalization, i.e., for cleaning different kinds of noise in the text. There have been several efforts towards cleaning or normalizing noisy text; however, many of the existing text normalization methods are supervised and require language-dependent resources or large amounts of training data that is difficult to obtain. We propose an unsupervised algorithm for text normalization that does not need any training data/human intervention. The proposed algorithm is applicable to text over different languages and can handle both machine-generated and human-generated noise. Experiments over several standard datasets show that text normalization through the proposed algorithm enables better retrieval and stance detection, as compared to that using several baseline text normalization methods.