ZSCRGAN: A GAN-based Expectation Maximization Model for Zero-Shot Retrieval of Images from Textual Descriptions.
Abstract
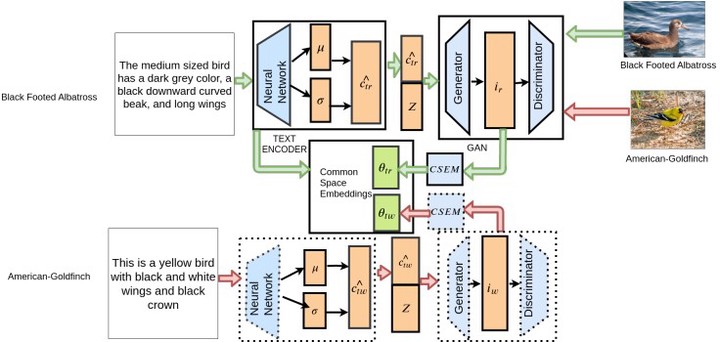
Most existing algorithms for cross-modal Information Retrieval are based on a supervised train-test setup, where a model learns to align the mode of the query (e.g., text) to the mode of the documents (e.g., images) from a given training set. Such a setup assumes that the training set contains an exhaustive representation of all possible classes of queries. In reality, a retrieval model may need to be deployed on previously unseen classes, which implies a zero-shot IR setup. In this paper, we propose a novel GAN-based model for zero-shot text to image retrieval. When given a textual description as the query, our model can retrieve relevant images in a zero-shot setup. The proposed model is trained using an Expectation-Maximization framework. Experiments on multiple benchmark datasets show that our proposed model comfortably outperforms several state-of-the-art zero-shot text to image retrieval models, as well as zero-shot classification and hashing models suitably used for retrieval.